
Today, I want to cover on-site search engine optimization (on-site or on-page SEO) and review all of the parts of your website that you’ll want to make sure are in top shape, in order to turbocharge your rankings on Google and other search engines.
We will cover Robots.txt, Sitemaps, Content Optimization, Duplicate Content, Hidden Content. Mobile-Friendly Site Structure, Page Speed, URL Structure, Site Security / HTTPS, Title Tags, Meta Description, Keywords, H1 H2 H3 Tags, Google Site Verification, Structured Data / Schema.org, and Rich Snippets.
I would like to begin with some takeaways to keep in mind throughout.
The first is that websites need to be machine-friendly and the most important machine is GoogleBot.
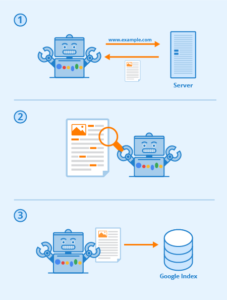 With all of the code needed to build a website and putting them together, it might seem counterintuitive to say they need to be machine-friendly, but if your website is not built to be read by Google, you will not be able to rank. The early code for the web was just about display and handling. It didn’t easily allow the web crawlers to understand what it is that they’re seeing.
To meet the high standards for ranking on Page 1 of Google for your most important keywords, you must add meta elements to the end markup of your page templates, and then make a regular practice of testing your site’s SEO, and update your site’s code and structure as needed.
We are going to focus this article on-site architecture and HTML code. These are the two most important pillars of effective on-page SEO.
I will cover the what, why and how of effective website architecture with a focus on SEO. We are going to start small so you don’t get too overwhelmed.
We’re going to start with crawling, after all before you can walk or run. You have to learn how to crawl.
Can search engines easily get around your site?
Google, Bing and Yahoo crawl your website to populate their indexes. Whether you are an individual or a business, these search engines are really important, and display results based on their crawling.
Bad or incomplete crawling can be influenced by a number of factors.
What is Robots.txt?
Robots.txt is a text file and it’s read by search engine spiders, you place it on the root of your domain. For most of you, that will be yourwebsite.com/robots.txt, so it tells the search engine spiders where they can and can’t go on your site, and it also should tell the spiders where to find the official list of your site’s URLs (basically a sitemap).
With all of the code needed to build a website and putting them together, it might seem counterintuitive to say they need to be machine-friendly, but if your website is not built to be read by Google, you will not be able to rank. The early code for the web was just about display and handling. It didn’t easily allow the web crawlers to understand what it is that they’re seeing.
To meet the high standards for ranking on Page 1 of Google for your most important keywords, you must add meta elements to the end markup of your page templates, and then make a regular practice of testing your site’s SEO, and update your site’s code and structure as needed.
We are going to focus this article on-site architecture and HTML code. These are the two most important pillars of effective on-page SEO.
I will cover the what, why and how of effective website architecture with a focus on SEO. We are going to start small so you don’t get too overwhelmed.
We’re going to start with crawling, after all before you can walk or run. You have to learn how to crawl.
Can search engines easily get around your site?
Google, Bing and Yahoo crawl your website to populate their indexes. Whether you are an individual or a business, these search engines are really important, and display results based on their crawling.
Bad or incomplete crawling can be influenced by a number of factors.
What is Robots.txt?
Robots.txt is a text file and it’s read by search engine spiders, you place it on the root of your domain. For most of you, that will be yourwebsite.com/robots.txt, so it tells the search engine spiders where they can and can’t go on your site, and it also should tell the spiders where to find the official list of your site’s URLs (basically a sitemap).
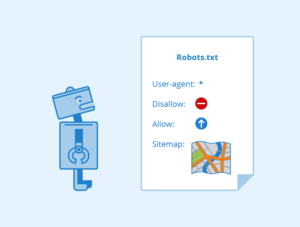 One of the things we just wanted to note, just allowing search engines to crawl part of your site, most of the reputable bots do follow this disallow instruction, but it doesn’t always 100% prevent something being indexed.
So Google might index the page if they discover it by following a link that someone else has put up on their website.
So if you are 100% sure you don’t want a crawler to get at a piece of your content, you should use meta tags, or of course, don’t publish it at all or add security.
What are Sitemaps?
One of the things we just wanted to note, just allowing search engines to crawl part of your site, most of the reputable bots do follow this disallow instruction, but it doesn’t always 100% prevent something being indexed.
So Google might index the page if they discover it by following a link that someone else has put up on their website.
So if you are 100% sure you don’t want a crawler to get at a piece of your content, you should use meta tags, or of course, don’t publish it at all or add security.
What are Sitemaps?
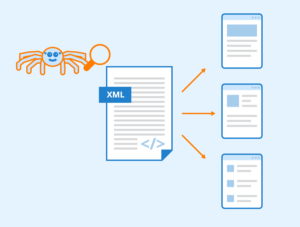 A sitemap is a file that lists the URLs of your site. Like a robots.txt file, a sitemap is placed on the root of your domain and it tells crawlers about your site, its content and its organization, and has a maximum size that you’ll want to pay attention to.
You can easily create a sitemap using Yoast or Screaming Frog.
While an XML sitemap is not a guarantee that your pages will be crawled, indexed or ranked, when you develop a well-organized XML sitemap and submit to Google and other search engines you are giving your website a great shot at getting pages indexed and ranked.
Fetch as Google / Fetch as Bingbot
Next, I want to briefly talk about Fetch as Google that enabled you to test how Google crawls or renders a URL on your site and you can use it to see whether Googlebot can access a page on your site, how it renders on the page and if any of the page resources are blocked. The old ‘Fetch as Googlebot’ feature was migrated to Google Search Console.
Bing has a similar program called Fetch as Bingbot, and is exactly the same concept as Fetch as Google and the new Search Console functionality. These resources allow you to see if it’s accessing all the parts of your site that you think it can, and if not, you can make the necessary changes and adjustments.
The Google Search Console offers a submit to index button on their webmaster tool. So that’s a nice feature of reviewing your text and also contributing a new page to their index at the same time.
Content and Duplicate Content
A sitemap is a file that lists the URLs of your site. Like a robots.txt file, a sitemap is placed on the root of your domain and it tells crawlers about your site, its content and its organization, and has a maximum size that you’ll want to pay attention to.
You can easily create a sitemap using Yoast or Screaming Frog.
While an XML sitemap is not a guarantee that your pages will be crawled, indexed or ranked, when you develop a well-organized XML sitemap and submit to Google and other search engines you are giving your website a great shot at getting pages indexed and ranked.
Fetch as Google / Fetch as Bingbot
Next, I want to briefly talk about Fetch as Google that enabled you to test how Google crawls or renders a URL on your site and you can use it to see whether Googlebot can access a page on your site, how it renders on the page and if any of the page resources are blocked. The old ‘Fetch as Googlebot’ feature was migrated to Google Search Console.
Bing has a similar program called Fetch as Bingbot, and is exactly the same concept as Fetch as Google and the new Search Console functionality. These resources allow you to see if it’s accessing all the parts of your site that you think it can, and if not, you can make the necessary changes and adjustments.
The Google Search Console offers a submit to index button on their webmaster tool. So that’s a nice feature of reviewing your text and also contributing a new page to their index at the same time.
Content and Duplicate Content
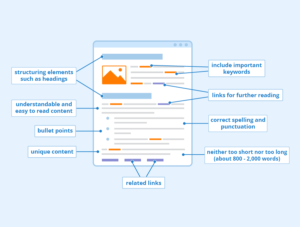 When evaluating content for relevance, Google and other search engines will look for keywords; evaluate URL structure; examine titles and descriptions; and analyze backlinks from other sites (and internal backlinks within your site) as signals of content relevance and authority.
In addition to relevant keywords, you want to include supporting content that contains related concepts and terms.
For example, when we develop content about “online reputation management“, we will include related terms like “reviews” and “brand management” or “reputation repair” to help Google.
You can do all the technical SEO steps outlined in this tutorial, but without relevant, user-focused content your page will not rank for competitive search terms.
When evaluating content for relevance, Google and other search engines will look for keywords; evaluate URL structure; examine titles and descriptions; and analyze backlinks from other sites (and internal backlinks within your site) as signals of content relevance and authority.
In addition to relevant keywords, you want to include supporting content that contains related concepts and terms.
For example, when we develop content about “online reputation management“, we will include related terms like “reviews” and “brand management” or “reputation repair” to help Google.
You can do all the technical SEO steps outlined in this tutorial, but without relevant, user-focused content your page will not rank for competitive search terms.
 Does your site manage duplicate content issues well? Duplicate content is content that appears on the web in more than one place — whether on your website or someone else’s.
If a single link is being served multiple ways, this causes the search engines to have to guess which version is the right one. For the same content, multiple URLs can exist. You might have it with HTTP or HTTPS, you might have the www protocol or not. It’s possible that you’ve put it in a folder or a sub-domain.
So there are six ways one piece of content could appear to a search engine crawler.
You don’t want to confuse Google!
Canonical URLs are one of the most effective tactics to resolve that issue. You put that link in your header and it tells the search engines which version is the version of record. Google has a page on its help blog about rel=canonicals (the “canonical link”).
Does your site manage duplicate content issues well? Duplicate content is content that appears on the web in more than one place — whether on your website or someone else’s.
If a single link is being served multiple ways, this causes the search engines to have to guess which version is the right one. For the same content, multiple URLs can exist. You might have it with HTTP or HTTPS, you might have the www protocol or not. It’s possible that you’ve put it in a folder or a sub-domain.
So there are six ways one piece of content could appear to a search engine crawler.
You don’t want to confuse Google!
Canonical URLs are one of the most effective tactics to resolve that issue. You put that link in your header and it tells the search engines which version is the version of record. Google has a page on its help blog about rel=canonicals (the “canonical link”).
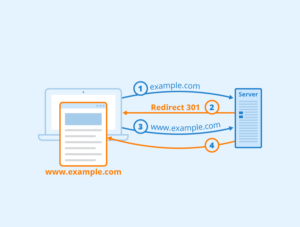 The Website indicated which version is the version of record, and so that’s one easy way to indicate which should be served on search engines or search results pages. Next, we have 301 redirects, and you’re going to use those when you’re permanently moving content on your site. It tells search engines that a page is permanently moved to a new location and that they should go and re-index it.
This should be for permanent moves, there are other kinds of redirects you can use if you think the content will be there just for temporarily moving purposes so just be aware of that. But the issue we see most is people who have fully redesigned their site, permanently moved everything to a new location, and are having trouble getting the crawlers to come and re-index their site.
You will want to be consistent when you’re linking internally I.e. make sure all of your page links are being linked to in the same exact way. So as I mentioned earlier there’re multiple ways for you to reference a particular piece of content. So if you’re wanting to link to it as HTTPS, do that throughout or if you’re using relative links like the slash page, make sure that’s consistent throughout your website.
For Google, you can set a preferred domain www or not www. You can also use 301s to redirect traffic from your non-preferred domain if you are having issues with that coming up in search results.
Another approach to deal with duplicate content is to add: <meta name=”robots” content=”noindex, nofollow> — to the HTML head of each page that you do not want search engines to index.
Hidden Content
Hidden content is a deceptive practice where you put text on the page that humans are not going to see because, for example, the font color is the same color as the background for instance. You don’t want to hide anything and cloaking is similar where you hide entire pages from your users but show them to search engines to try to up your SEO juice. Don’t hide anything, try to make everything match and you won’t get penalized by Google.
Mobile-Friendly as a Ranking Signal
The Website indicated which version is the version of record, and so that’s one easy way to indicate which should be served on search engines or search results pages. Next, we have 301 redirects, and you’re going to use those when you’re permanently moving content on your site. It tells search engines that a page is permanently moved to a new location and that they should go and re-index it.
This should be for permanent moves, there are other kinds of redirects you can use if you think the content will be there just for temporarily moving purposes so just be aware of that. But the issue we see most is people who have fully redesigned their site, permanently moved everything to a new location, and are having trouble getting the crawlers to come and re-index their site.
You will want to be consistent when you’re linking internally I.e. make sure all of your page links are being linked to in the same exact way. So as I mentioned earlier there’re multiple ways for you to reference a particular piece of content. So if you’re wanting to link to it as HTTPS, do that throughout or if you’re using relative links like the slash page, make sure that’s consistent throughout your website.
For Google, you can set a preferred domain www or not www. You can also use 301s to redirect traffic from your non-preferred domain if you are having issues with that coming up in search results.
Another approach to deal with duplicate content is to add: <meta name=”robots” content=”noindex, nofollow> — to the HTML head of each page that you do not want search engines to index.
Hidden Content
Hidden content is a deceptive practice where you put text on the page that humans are not going to see because, for example, the font color is the same color as the background for instance. You don’t want to hide anything and cloaking is similar where you hide entire pages from your users but show them to search engines to try to up your SEO juice. Don’t hide anything, try to make everything match and you won’t get penalized by Google.
Mobile-Friendly as a Ranking Signal
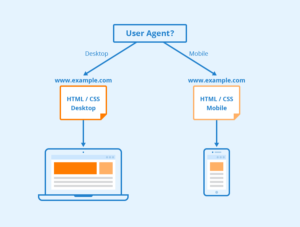 Does your site work well for mobile devices? In spring 2016 Google increased the impact of mobile-friendliness as a ranking signal. Mobile-friendliness is so important for a multitude of different reasons and ranking is just one of them.
In the USA, 94% of people with smartphones search for local information on their phones, and 77% of mobile searches occur at home or at work, places where desktop computers are likely to be present.
Mobile is how people are actually accessing your website’s information. Google offers a free mobile-friendly test.
Google will show you a little preview of how your site looks on a device and whether this page is mobile-friendly. It’s easy to use and it’ll give you instructions to fix any issues you might encounter with making something mobile-friendly.
Page Speed
Does your site load quickly? We have all notorious short attention spans. So if users are not able to access your site, and it’s loading slowly, they’re going to abandon it. This is not as great of an impact on your SEO ranking as some of the other factors. Google has noted this all the way back in 2010, but it’s really critical to overall UX.
People are not going to stay on site if they can’t access to your materials.
Google offers PageSpeed Insights, and provides suggestions on how to improve it.
Does your site work well for mobile devices? In spring 2016 Google increased the impact of mobile-friendliness as a ranking signal. Mobile-friendliness is so important for a multitude of different reasons and ranking is just one of them.
In the USA, 94% of people with smartphones search for local information on their phones, and 77% of mobile searches occur at home or at work, places where desktop computers are likely to be present.
Mobile is how people are actually accessing your website’s information. Google offers a free mobile-friendly test.
Google will show you a little preview of how your site looks on a device and whether this page is mobile-friendly. It’s easy to use and it’ll give you instructions to fix any issues you might encounter with making something mobile-friendly.
Page Speed
Does your site load quickly? We have all notorious short attention spans. So if users are not able to access your site, and it’s loading slowly, they’re going to abandon it. This is not as great of an impact on your SEO ranking as some of the other factors. Google has noted this all the way back in 2010, but it’s really critical to overall UX.
People are not going to stay on site if they can’t access to your materials.
Google offers PageSpeed Insights, and provides suggestions on how to improve it.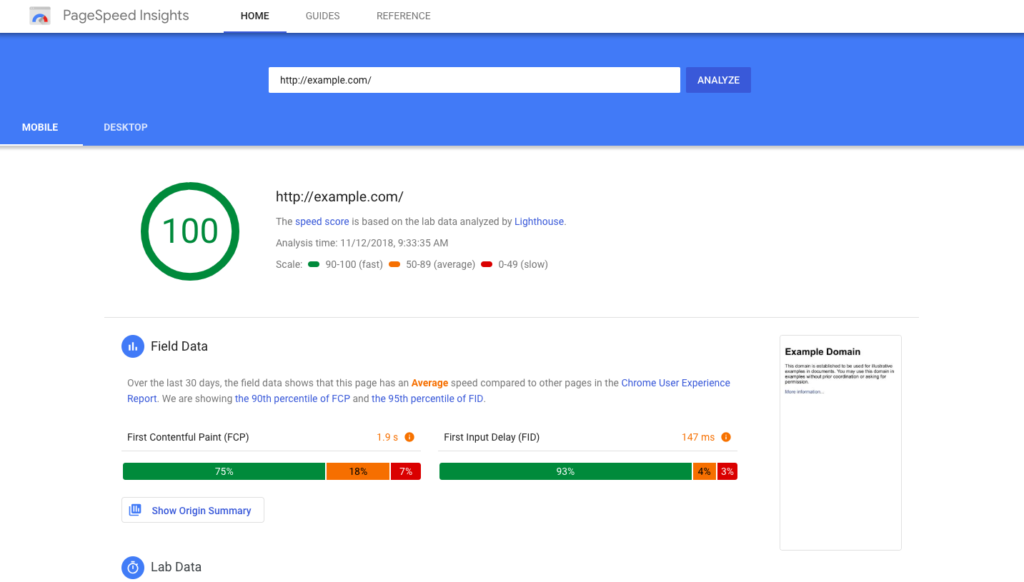 This is a really easy way to give you useful, actionable insights and shows you how to fix page speed issues on desktop and mobile.
Site speed also affects the ability of the spiders to get around your site. In terms of facilitating a crawl and making sure that Google can happily get through your content without any timeouts, site speed is a factor there as well.
URL Structure
Do your URLs contain meaningful keywords to page topics? Use simple human-friendly URLs and use punctuation. Google has said that like yourwebsite.com/red-balloon is more useful to a crawler than “redballoon” all as one word, and they recommend that you use hyphens instead of underscores.
HTTPS and Site Security
Does your site provide a secure connection for visitors? Since 2014 Google has been advocating for HTTPS Everywhere. When properly configured, HTTPS can provide a fast, secure connection that offers a level of privacy and reliability that users should expect. The W3C’s Technical Architecture Group has argued persuasively that the web should actively prefer secure connections and transition entirely to HTTPS.
This is a more lightweight ranking signal, but it’s just really important beyond relevancy rankings. It is easy to transition to HTTPS with your website host.
Title Tags
When you look at the title tags for your website, make sure that they are unique to the page, meaning that they are not your site or company name. The title is used to display at the top of the browser either in the tab or in the browser window, but it also is a signal to search engines what they should display in their search results page as a clickable link in their results.
This is a really easy way to give you useful, actionable insights and shows you how to fix page speed issues on desktop and mobile.
Site speed also affects the ability of the spiders to get around your site. In terms of facilitating a crawl and making sure that Google can happily get through your content without any timeouts, site speed is a factor there as well.
URL Structure
Do your URLs contain meaningful keywords to page topics? Use simple human-friendly URLs and use punctuation. Google has said that like yourwebsite.com/red-balloon is more useful to a crawler than “redballoon” all as one word, and they recommend that you use hyphens instead of underscores.
HTTPS and Site Security
Does your site provide a secure connection for visitors? Since 2014 Google has been advocating for HTTPS Everywhere. When properly configured, HTTPS can provide a fast, secure connection that offers a level of privacy and reliability that users should expect. The W3C’s Technical Architecture Group has argued persuasively that the web should actively prefer secure connections and transition entirely to HTTPS.
This is a more lightweight ranking signal, but it’s just really important beyond relevancy rankings. It is easy to transition to HTTPS with your website host.
Title Tags
When you look at the title tags for your website, make sure that they are unique to the page, meaning that they are not your site or company name. The title is used to display at the top of the browser either in the tab or in the browser window, but it also is a signal to search engines what they should display in their search results page as a clickable link in their results.
 If you want to include the site name in the title tag, what you should do is include it after a pipe character like a dash to clearly differentiate the title of the page. The title tag contents should be descriptive and short. So ideally, it will match the title of your page but if it doesn’t match exactly, it should be both descriptive of the content on the page and it should also be short.
The recommendation from Google is to have it in the 60 to 70 characters range. This is by itself a practical recommendation because the search results list is only so wide, and you don’t want to have the page title of your item in their search results get truncated. So that’s the recommendation for brief titles.
In addition to being descriptive of the content that’s on the page, you want to try to make sure that the way that you title the page will match as much as possible the terms or keywords that searchers are entering and they’re using in their queries so that Google and Bing have an easier time making that match between user intent, and the item that will be serving that intent.
Description
The next key on-page element is the description. The description is included in the head of your page. A meta description (sometimes called a meta description attribute or tag) is an HTML element that is used to summarize and describe the content of your page.
If it is done well, this is used as the snippet text below your item on the search engine results page. So it should be unique to the page and descriptive of the content on the page. It should also be relatively short so the recommendation is to make the description approximately 155 characters including spaces. The reason why there’s not an actual character max is probably that Google measures the length of their descriptions in pixels, and not in characters and so if you have description text that includes a lot of Ms, then you’re not going to be able to fit as many words in it as if your description includes a lot of Ls and Is.
In case your description does run longer than what Google is willing to show on their search results page as their snippet, you want to make sure that the most substantive terms for your page that will best advertise the content to the searcher are front-loaded at the beginning of your description so that they’ll be able to see those and make an informed decision about whether to click on that item.
Headers – H1 H2 H3 Tags
If you want to include the site name in the title tag, what you should do is include it after a pipe character like a dash to clearly differentiate the title of the page. The title tag contents should be descriptive and short. So ideally, it will match the title of your page but if it doesn’t match exactly, it should be both descriptive of the content on the page and it should also be short.
The recommendation from Google is to have it in the 60 to 70 characters range. This is by itself a practical recommendation because the search results list is only so wide, and you don’t want to have the page title of your item in their search results get truncated. So that’s the recommendation for brief titles.
In addition to being descriptive of the content that’s on the page, you want to try to make sure that the way that you title the page will match as much as possible the terms or keywords that searchers are entering and they’re using in their queries so that Google and Bing have an easier time making that match between user intent, and the item that will be serving that intent.
Description
The next key on-page element is the description. The description is included in the head of your page. A meta description (sometimes called a meta description attribute or tag) is an HTML element that is used to summarize and describe the content of your page.
If it is done well, this is used as the snippet text below your item on the search engine results page. So it should be unique to the page and descriptive of the content on the page. It should also be relatively short so the recommendation is to make the description approximately 155 characters including spaces. The reason why there’s not an actual character max is probably that Google measures the length of their descriptions in pixels, and not in characters and so if you have description text that includes a lot of Ms, then you’re not going to be able to fit as many words in it as if your description includes a lot of Ls and Is.
In case your description does run longer than what Google is willing to show on their search results page as their snippet, you want to make sure that the most substantive terms for your page that will best advertise the content to the searcher are front-loaded at the beginning of your description so that they’ll be able to see those and make an informed decision about whether to click on that item.
Headers – H1 H2 H3 Tags
 Headers are actually down in the body of the page and these are your H1 H2 H3 tags. So definitely use H tags. Sometimes if you’re looking through for best practices around headers you might also see the word heading tags
When header tags were initially introduced they were pre-CSS, so pre-Cascading Style Sheets where you could declare the display style of your website in a separate set of elements, and then… so the <H1> tag was the biggest and then <H2> <H3> got gradually smaller and smaller and they were bold and big and then reduced in size.
Once CSS was introduced the header or heading tags migrated in purpose to describe the outline of your page, and so the H1 tag now indicates to the search engine spiders that that is the title of your page.
Ideally, the H1 tag and the title tag will match, but they don’t have to be exactly the same. The H1 tag tells the spider, “This is where the content begins.” It also tells the spider that, “you take good care of your code and our being intentional about the quality of your page structure.” And then as you head down the structure of your page they need to be in order. If your page has three sections you would have three H2 tags and within each could be an H3 tag, etc.
You can jump straight from H1 to H3 but please don’t start at H2, it confuses Google and may hurt your SEO.
Also in the head of your pages, you will hopefully have many, many meta tags, and shares a summary of the meta tags that Google understands. They actually understand more than this, but this is a great starting place from an SEO perspective.
Keywords
You should use your main keyword(s) within the opening and closing paragraphs of your content and use the secondary and main keywords within the body of the content.
If you have an Adwords account, you may want to look into Google’s Keyword Tool, it is very helpful for finding new keyword ideas that have search volume and ranking potential.
Headers are actually down in the body of the page and these are your H1 H2 H3 tags. So definitely use H tags. Sometimes if you’re looking through for best practices around headers you might also see the word heading tags
When header tags were initially introduced they were pre-CSS, so pre-Cascading Style Sheets where you could declare the display style of your website in a separate set of elements, and then… so the <H1> tag was the biggest and then <H2> <H3> got gradually smaller and smaller and they were bold and big and then reduced in size.
Once CSS was introduced the header or heading tags migrated in purpose to describe the outline of your page, and so the H1 tag now indicates to the search engine spiders that that is the title of your page.
Ideally, the H1 tag and the title tag will match, but they don’t have to be exactly the same. The H1 tag tells the spider, “This is where the content begins.” It also tells the spider that, “you take good care of your code and our being intentional about the quality of your page structure.” And then as you head down the structure of your page they need to be in order. If your page has three sections you would have three H2 tags and within each could be an H3 tag, etc.
You can jump straight from H1 to H3 but please don’t start at H2, it confuses Google and may hurt your SEO.
Also in the head of your pages, you will hopefully have many, many meta tags, and shares a summary of the meta tags that Google understands. They actually understand more than this, but this is a great starting place from an SEO perspective.
Keywords
You should use your main keyword(s) within the opening and closing paragraphs of your content and use the secondary and main keywords within the body of the content.
If you have an Adwords account, you may want to look into Google’s Keyword Tool, it is very helpful for finding new keyword ideas that have search volume and ranking potential.
 One of the meta tags available on the back-end of your site is keywords. It is now usually ignored by search engines. Be very careful if you want to use the keywords meta tag, and then similarly in the meta description. It should be standard English, proper grammar, and describe the content of the page and not be a list of keywords to try to capture all of those possible matches with query terms.
Another point about keywords is that when developing content for your website, you could go overboard — what’s called keyword stuffing and risk a penalty for your website. You have all experienced keyword stuffing in your Amazon searches where you’re looking for one thing and then there’s an item for sale that is completely different because of additional keywords used in the description. It is an unnecessary redundancy in trying to get all those words in to game the search system to show the item for all of these different search queries that might be entered. Don’t do that.
Google Site Verification
Google Site Verification is for linking your site into the Google Search Console or Google Webmaster Tools, as it used to be called, and then also they have different ways of matching the content up with other content and then the character set tells it what kind of encoding that the page includes. So that’s when you want to tell Google information about your site and when you want to tell it not to do things to block it from doing things. So actually mentioned earlier disallowing indexing in the robots.txt file. So if you wanted to do that on the page level, then you could disallow all robots and there are a lot of things that you can tell it to do, no index, no follow, lots and lots of things.
You’ve probably all been to a site that is published in another language and Google offers a “This site is in French, would you like to translate it?” And it’s got a translate button and a note button. So if you want to block that translation option, then you can use this Google content no translate meta tag, and you’ve probably been on Google.com and gotten a search result, and then within the search result, there has been a site-specific search box. So if for whatever reason you don’t want to have that happening with your site, you can use this Google meta tag, no site link search box feature.
Structured Data – Schema.org and Open Graph Protocol
One of the meta tags available on the back-end of your site is keywords. It is now usually ignored by search engines. Be very careful if you want to use the keywords meta tag, and then similarly in the meta description. It should be standard English, proper grammar, and describe the content of the page and not be a list of keywords to try to capture all of those possible matches with query terms.
Another point about keywords is that when developing content for your website, you could go overboard — what’s called keyword stuffing and risk a penalty for your website. You have all experienced keyword stuffing in your Amazon searches where you’re looking for one thing and then there’s an item for sale that is completely different because of additional keywords used in the description. It is an unnecessary redundancy in trying to get all those words in to game the search system to show the item for all of these different search queries that might be entered. Don’t do that.
Google Site Verification
Google Site Verification is for linking your site into the Google Search Console or Google Webmaster Tools, as it used to be called, and then also they have different ways of matching the content up with other content and then the character set tells it what kind of encoding that the page includes. So that’s when you want to tell Google information about your site and when you want to tell it not to do things to block it from doing things. So actually mentioned earlier disallowing indexing in the robots.txt file. So if you wanted to do that on the page level, then you could disallow all robots and there are a lot of things that you can tell it to do, no index, no follow, lots and lots of things.
You’ve probably all been to a site that is published in another language and Google offers a “This site is in French, would you like to translate it?” And it’s got a translate button and a note button. So if you want to block that translation option, then you can use this Google content no translate meta tag, and you’ve probably been on Google.com and gotten a search result, and then within the search result, there has been a site-specific search box. So if for whatever reason you don’t want to have that happening with your site, you can use this Google meta tag, no site link search box feature.
Structured Data – Schema.org and Open Graph Protocol
 Google uses structured data to enhance listings. When we talk about how your site needs to be machine-friendly, the structure of data is really where this is critical.
Featured Snippets / Rich Snippets
Google searches frequently highlights answers at the top of the page. These are called rich snippets or featured snippets. Whether in a paragraph, list, or table format, featured snippets seek to answer users’ questions and search queries and are a valuable source of traffic when your site is properly optimized.
You have probably seen on the right-hand side of the screen they show images and summary information called knowledge cards on your search results pages. Those are enabled by a structured markup so their machines are able to look through the content of the page and interpret the information that they’re seeing in that text.
This is also referred to as semantic markup, it is the meaning of the semantic markup to convey the meaning of the site. So what does that mean? Essentially semantic markup deals in two things, entities and attributes and essentially those are nouns and adjectives at the web-scale. We need to know what is the thing that we’re looking at and what it is like.
In terms of implementing structured markup, there are a number of options available to you. So the one promoted by Google and other major entities is the Schema.org set of markups. There’s also Open Graph protocol which you can identify as meta elements that begin with og: This is a framework that is employed extensively by Facebook and so if you want to control how Facebook sees your screen, you’ll want to include the Open Graph markup in your pages. There are also Dublin Core metadata options that begin with dc: and a lot more.
Google does prefer the Schema.org markup, they are heavily involved in the development of this, and if you don’t have experience in looking at entity relationship diagrams and thinking about how all of the pieces parts of things fit together it can be a little bit overwhelming.
Data sets may have unique attributes within it from articles or maps or webpages. In order for the nearest location to show up as a card in that upper right-hand corner of the search results page, you actually do need to be listed in Google My Business. You should be able to enter all of your location data into the Google My Business listing, and then they would use that to feed those location cards in the Google search results, and then also the postal address is something that you could use for the address that you’ve got in your footer or other places throughout your site. Hopefully, you would be able to make a change just once in your template and not have to change it on every page assuming that you’ve got a site that inserts your footer content for you.
There are three different ways that you can present schema.org elements. So the one that Google recommends the most is the JSON-LD format, this is included as a block of script in the head of your page. You might want to do a bit of research to see if you could use JSON in combination with the structure of your current content. Another option is RDFa, and then Microdata both of which are expressed as inline properties in the body of your page.
If you are looking on a google.com search results page, and instead of a URL underneath the clickable title, you see the set of breadcrumbs from a site. They’re feeding that from this breadcrumbs markup.
One point about a website’s homepage is that you have the opportunity to control your site name as Google displays it in the search results. This is often shown as the first and most basic layer of a breadcrumbs list, but in the head of your page, you can add an item property of name to the title link and then it will use the text of the title link to inform your site name on the Google search results. One thing that I would caution you if you want to do this is, they recommend that it be simple and concise so that it doesn’t clutter up the search results essentially. For example, their name property is Google and not Google Inc.
Finally, you should know that you can trigger Google Site Search for your site, by telling it about potential actions and then you can tell it how to run a search on your site.
Final Thoughts
I hope this article was helpful in understanding some of the key elements of on-page or on-site SEO.
We covered Robots.txt, Sitemaps, Content Optimization, Duplicate Content, Hidden Content. Mobile-Friendly Site Structure, Page Speed, URL Structure, Site Security / HTTPS, Title Tags, Meta Description, Keywords, H1 H2 H3 Tags, Google Site Verification, Structured Data / Schema.org, and Rich Snippets.
Google uses structured data to enhance listings. When we talk about how your site needs to be machine-friendly, the structure of data is really where this is critical.
Featured Snippets / Rich Snippets
Google searches frequently highlights answers at the top of the page. These are called rich snippets or featured snippets. Whether in a paragraph, list, or table format, featured snippets seek to answer users’ questions and search queries and are a valuable source of traffic when your site is properly optimized.
You have probably seen on the right-hand side of the screen they show images and summary information called knowledge cards on your search results pages. Those are enabled by a structured markup so their machines are able to look through the content of the page and interpret the information that they’re seeing in that text.
This is also referred to as semantic markup, it is the meaning of the semantic markup to convey the meaning of the site. So what does that mean? Essentially semantic markup deals in two things, entities and attributes and essentially those are nouns and adjectives at the web-scale. We need to know what is the thing that we’re looking at and what it is like.
In terms of implementing structured markup, there are a number of options available to you. So the one promoted by Google and other major entities is the Schema.org set of markups. There’s also Open Graph protocol which you can identify as meta elements that begin with og: This is a framework that is employed extensively by Facebook and so if you want to control how Facebook sees your screen, you’ll want to include the Open Graph markup in your pages. There are also Dublin Core metadata options that begin with dc: and a lot more.
Google does prefer the Schema.org markup, they are heavily involved in the development of this, and if you don’t have experience in looking at entity relationship diagrams and thinking about how all of the pieces parts of things fit together it can be a little bit overwhelming.
Data sets may have unique attributes within it from articles or maps or webpages. In order for the nearest location to show up as a card in that upper right-hand corner of the search results page, you actually do need to be listed in Google My Business. You should be able to enter all of your location data into the Google My Business listing, and then they would use that to feed those location cards in the Google search results, and then also the postal address is something that you could use for the address that you’ve got in your footer or other places throughout your site. Hopefully, you would be able to make a change just once in your template and not have to change it on every page assuming that you’ve got a site that inserts your footer content for you.
There are three different ways that you can present schema.org elements. So the one that Google recommends the most is the JSON-LD format, this is included as a block of script in the head of your page. You might want to do a bit of research to see if you could use JSON in combination with the structure of your current content. Another option is RDFa, and then Microdata both of which are expressed as inline properties in the body of your page.
If you are looking on a google.com search results page, and instead of a URL underneath the clickable title, you see the set of breadcrumbs from a site. They’re feeding that from this breadcrumbs markup.
One point about a website’s homepage is that you have the opportunity to control your site name as Google displays it in the search results. This is often shown as the first and most basic layer of a breadcrumbs list, but in the head of your page, you can add an item property of name to the title link and then it will use the text of the title link to inform your site name on the Google search results. One thing that I would caution you if you want to do this is, they recommend that it be simple and concise so that it doesn’t clutter up the search results essentially. For example, their name property is Google and not Google Inc.
Finally, you should know that you can trigger Google Site Search for your site, by telling it about potential actions and then you can tell it how to run a search on your site.
Final Thoughts
I hope this article was helpful in understanding some of the key elements of on-page or on-site SEO.
We covered Robots.txt, Sitemaps, Content Optimization, Duplicate Content, Hidden Content. Mobile-Friendly Site Structure, Page Speed, URL Structure, Site Security / HTTPS, Title Tags, Meta Description, Keywords, H1 H2 H3 Tags, Google Site Verification, Structured Data / Schema.org, and Rich Snippets.
With all of the code needed to build a website and putting them together, it might seem counterintuitive to say they need to be machine-friendly, but if your website is not built to be read by Google, you will not be able to rank. The early code for the web was just about display and handling. It didn’t easily allow the web crawlers to understand what it is that they’re seeing.
To meet the high standards for ranking on Page 1 of Google for your most important keywords, you must add meta elements to the end markup of your page templates, and then make a regular practice of testing your site’s SEO, and update your site’s code and structure as needed.
We are going to focus this article on-site architecture and HTML code. These are the two most important pillars of effective on-page SEO.
I will cover the what, why and how of effective website architecture with a focus on SEO. We are going to start small so you don’t get too overwhelmed.
We’re going to start with crawling, after all before you can walk or run. You have to learn how to crawl.
Can search engines easily get around your site?
Google, Bing and Yahoo crawl your website to populate their indexes. Whether you are an individual or a business, these search engines are really important, and display results based on their crawling.
Bad or incomplete crawling can be influenced by a number of factors.
What is Robots.txt?
Robots.txt is a text file and it’s read by search engine spiders, you place it on the root of your domain. For most of you, that will be yourwebsite.com/robots.txt, so it tells the search engine spiders where they can and can’t go on your site, and it also should tell the spiders where to find the official list of your site’s URLs (basically a sitemap).
One of the things we just wanted to note, just allowing search engines to crawl part of your site, most of the reputable bots do follow this disallow instruction, but it doesn’t always 100% prevent something being indexed.
So Google might index the page if they discover it by following a link that someone else has put up on their website.
So if you are 100% sure you don’t want a crawler to get at a piece of your content, you should use meta tags, or of course, don’t publish it at all or add security.
What are Sitemaps?
A sitemap is a file that lists the URLs of your site. Like a robots.txt file, a sitemap is placed on the root of your domain and it tells crawlers about your site, its content and its organization, and has a maximum size that you’ll want to pay attention to.
You can easily create a sitemap using Yoast or Screaming Frog.
While an XML sitemap is not a guarantee that your pages will be crawled, indexed or ranked, when you develop a well-organized XML sitemap and submit to Google and other search engines you are giving your website a great shot at getting pages indexed and ranked.
Fetch as Google / Fetch as Bingbot
Next, I want to briefly talk about Fetch as Google that enabled you to test how Google crawls or renders a URL on your site and you can use it to see whether Googlebot can access a page on your site, how it renders on the page and if any of the page resources are blocked. The old ‘Fetch as Googlebot’ feature was migrated to Google Search Console.
Bing has a similar program called Fetch as Bingbot, and is exactly the same concept as Fetch as Google and the new Search Console functionality. These resources allow you to see if it’s accessing all the parts of your site that you think it can, and if not, you can make the necessary changes and adjustments.
The Google Search Console offers a submit to index button on their webmaster tool. So that’s a nice feature of reviewing your text and also contributing a new page to their index at the same time.
Content and Duplicate Content
When evaluating content for relevance, Google and other search engines will look for keywords; evaluate URL structure; examine titles and descriptions; and analyze backlinks from other sites (and internal backlinks within your site) as signals of content relevance and authority.
In addition to relevant keywords, you want to include supporting content that contains related concepts and terms.
For example, when we develop content about “online reputation management“, we will include related terms like “reviews” and “brand management” or “reputation repair” to help Google.
You can do all the technical SEO steps outlined in this tutorial, but without relevant, user-focused content your page will not rank for competitive search terms.
Does your site manage duplicate content issues well? Duplicate content is content that appears on the web in more than one place — whether on your website or someone else’s.
If a single link is being served multiple ways, this causes the search engines to have to guess which version is the right one. For the same content, multiple URLs can exist. You might have it with HTTP or HTTPS, you might have the www protocol or not. It’s possible that you’ve put it in a folder or a sub-domain.
So there are six ways one piece of content could appear to a search engine crawler.
You don’t want to confuse Google!
Canonical URLs are one of the most effective tactics to resolve that issue. You put that link in your header and it tells the search engines which version is the version of record. Google has a page on its help blog about rel=canonicals (the “canonical link”).
The Website indicated which version is the version of record, and so that’s one easy way to indicate which should be served on search engines or search results pages. Next, we have 301 redirects, and you’re going to use those when you’re permanently moving content on your site. It tells search engines that a page is permanently moved to a new location and that they should go and re-index it.
This should be for permanent moves, there are other kinds of redirects you can use if you think the content will be there just for temporarily moving purposes so just be aware of that. But the issue we see most is people who have fully redesigned their site, permanently moved everything to a new location, and are having trouble getting the crawlers to come and re-index their site.
You will want to be consistent when you’re linking internally I.e. make sure all of your page links are being linked to in the same exact way. So as I mentioned earlier there’re multiple ways for you to reference a particular piece of content. So if you’re wanting to link to it as HTTPS, do that throughout or if you’re using relative links like the slash page, make sure that’s consistent throughout your website.
For Google, you can set a preferred domain www or not www. You can also use 301s to redirect traffic from your non-preferred domain if you are having issues with that coming up in search results.
Another approach to deal with duplicate content is to add: <meta name=”robots” content=”noindex, nofollow> — to the HTML head of each page that you do not want search engines to index.
Hidden Content
Hidden content is a deceptive practice where you put text on the page that humans are not going to see because, for example, the font color is the same color as the background for instance. You don’t want to hide anything and cloaking is similar where you hide entire pages from your users but show them to search engines to try to up your SEO juice. Don’t hide anything, try to make everything match and you won’t get penalized by Google.
Mobile-Friendly as a Ranking Signal
Does your site work well for mobile devices? In spring 2016 Google increased the impact of mobile-friendliness as a ranking signal. Mobile-friendliness is so important for a multitude of different reasons and ranking is just one of them.
In the USA, 94% of people with smartphones search for local information on their phones, and 77% of mobile searches occur at home or at work, places where desktop computers are likely to be present.
Mobile is how people are actually accessing your website’s information. Google offers a free mobile-friendly test.
Google will show you a little preview of how your site looks on a device and whether this page is mobile-friendly. It’s easy to use and it’ll give you instructions to fix any issues you might encounter with making something mobile-friendly.
Page Speed
Does your site load quickly? We have all notorious short attention spans. So if users are not able to access your site, and it’s loading slowly, they’re going to abandon it. This is not as great of an impact on your SEO ranking as some of the other factors. Google has noted this all the way back in 2010, but it’s really critical to overall UX.
People are not going to stay on site if they can’t access to your materials.
Google offers PageSpeed Insights, and provides suggestions on how to improve it.
This is a really easy way to give you useful, actionable insights and shows you how to fix page speed issues on desktop and mobile.
Site speed also affects the ability of the spiders to get around your site. In terms of facilitating a crawl and making sure that Google can happily get through your content without any timeouts, site speed is a factor there as well.
URL Structure
Do your URLs contain meaningful keywords to page topics? Use simple human-friendly URLs and use punctuation. Google has said that like yourwebsite.com/red-balloon is more useful to a crawler than “redballoon” all as one word, and they recommend that you use hyphens instead of underscores.
HTTPS and Site Security
Does your site provide a secure connection for visitors? Since 2014 Google has been advocating for HTTPS Everywhere. When properly configured, HTTPS can provide a fast, secure connection that offers a level of privacy and reliability that users should expect. The W3C’s Technical Architecture Group has argued persuasively that the web should actively prefer secure connections and transition entirely to HTTPS.
This is a more lightweight ranking signal, but it’s just really important beyond relevancy rankings. It is easy to transition to HTTPS with your website host.
Title Tags
When you look at the title tags for your website, make sure that they are unique to the page, meaning that they are not your site or company name. The title is used to display at the top of the browser either in the tab or in the browser window, but it also is a signal to search engines what they should display in their search results page as a clickable link in their results.
If you want to include the site name in the title tag, what you should do is include it after a pipe character like a dash to clearly differentiate the title of the page. The title tag contents should be descriptive and short. So ideally, it will match the title of your page but if it doesn’t match exactly, it should be both descriptive of the content on the page and it should also be short.
The recommendation from Google is to have it in the 60 to 70 characters range. This is by itself a practical recommendation because the search results list is only so wide, and you don’t want to have the page title of your item in their search results get truncated. So that’s the recommendation for brief titles.
In addition to being descriptive of the content that’s on the page, you want to try to make sure that the way that you title the page will match as much as possible the terms or keywords that searchers are entering and they’re using in their queries so that Google and Bing have an easier time making that match between user intent, and the item that will be serving that intent.
Description
The next key on-page element is the description. The description is included in the head of your page. A meta description (sometimes called a meta description attribute or tag) is an HTML element that is used to summarize and describe the content of your page.
If it is done well, this is used as the snippet text below your item on the search engine results page. So it should be unique to the page and descriptive of the content on the page. It should also be relatively short so the recommendation is to make the description approximately 155 characters including spaces. The reason why there’s not an actual character max is probably that Google measures the length of their descriptions in pixels, and not in characters and so if you have description text that includes a lot of Ms, then you’re not going to be able to fit as many words in it as if your description includes a lot of Ls and Is.
In case your description does run longer than what Google is willing to show on their search results page as their snippet, you want to make sure that the most substantive terms for your page that will best advertise the content to the searcher are front-loaded at the beginning of your description so that they’ll be able to see those and make an informed decision about whether to click on that item.
Headers – H1 H2 H3 Tags
Headers are actually down in the body of the page and these are your H1 H2 H3 tags. So definitely use H tags. Sometimes if you’re looking through for best practices around headers you might also see the word heading tags
When header tags were initially introduced they were pre-CSS, so pre-Cascading Style Sheets where you could declare the display style of your website in a separate set of elements, and then… so the <H1> tag was the biggest and then <H2> <H3> got gradually smaller and smaller and they were bold and big and then reduced in size.
Once CSS was introduced the header or heading tags migrated in purpose to describe the outline of your page, and so the H1 tag now indicates to the search engine spiders that that is the title of your page.
Ideally, the H1 tag and the title tag will match, but they don’t have to be exactly the same. The H1 tag tells the spider, “This is where the content begins.” It also tells the spider that, “you take good care of your code and our being intentional about the quality of your page structure.” And then as you head down the structure of your page they need to be in order. If your page has three sections you would have three H2 tags and within each could be an H3 tag, etc.
You can jump straight from H1 to H3 but please don’t start at H2, it confuses Google and may hurt your SEO.
Also in the head of your pages, you will hopefully have many, many meta tags, and shares a summary of the meta tags that Google understands. They actually understand more than this, but this is a great starting place from an SEO perspective.
Keywords
You should use your main keyword(s) within the opening and closing paragraphs of your content and use the secondary and main keywords within the body of the content.
If you have an Adwords account, you may want to look into Google’s Keyword Tool, it is very helpful for finding new keyword ideas that have search volume and ranking potential.
One of the meta tags available on the back-end of your site is keywords. It is now usually ignored by search engines. Be very careful if you want to use the keywords meta tag, and then similarly in the meta description. It should be standard English, proper grammar, and describe the content of the page and not be a list of keywords to try to capture all of those possible matches with query terms.
Another point about keywords is that when developing content for your website, you could go overboard — what’s called keyword stuffing and risk a penalty for your website. You have all experienced keyword stuffing in your Amazon searches where you’re looking for one thing and then there’s an item for sale that is completely different because of additional keywords used in the description. It is an unnecessary redundancy in trying to get all those words in to game the search system to show the item for all of these different search queries that might be entered. Don’t do that.
Google Site Verification
Google Site Verification is for linking your site into the Google Search Console or Google Webmaster Tools, as it used to be called, and then also they have different ways of matching the content up with other content and then the character set tells it what kind of encoding that the page includes. So that’s when you want to tell Google information about your site and when you want to tell it not to do things to block it from doing things. So actually mentioned earlier disallowing indexing in the robots.txt file. So if you wanted to do that on the page level, then you could disallow all robots and there are a lot of things that you can tell it to do, no index, no follow, lots and lots of things.
You’ve probably all been to a site that is published in another language and Google offers a “This site is in French, would you like to translate it?” And it’s got a translate button and a note button. So if you want to block that translation option, then you can use this Google content no translate meta tag, and you’ve probably been on Google.com and gotten a search result, and then within the search result, there has been a site-specific search box. So if for whatever reason you don’t want to have that happening with your site, you can use this Google meta tag, no site link search box feature.
Structured Data – Schema.org and Open Graph Protocol
Google uses structured data to enhance listings. When we talk about how your site needs to be machine-friendly, the structure of data is really where this is critical.
Featured Snippets / Rich Snippets
Google searches frequently highlights answers at the top of the page. These are called rich snippets or featured snippets. Whether in a paragraph, list, or table format, featured snippets seek to answer users’ questions and search queries and are a valuable source of traffic when your site is properly optimized.
You have probably seen on the right-hand side of the screen they show images and summary information called knowledge cards on your search results pages. Those are enabled by a structured markup so their machines are able to look through the content of the page and interpret the information that they’re seeing in that text.
This is also referred to as semantic markup, it is the meaning of the semantic markup to convey the meaning of the site. So what does that mean? Essentially semantic markup deals in two things, entities and attributes and essentially those are nouns and adjectives at the web-scale. We need to know what is the thing that we’re looking at and what it is like.
In terms of implementing structured markup, there are a number of options available to you. So the one promoted by Google and other major entities is the Schema.org set of markups. There’s also Open Graph protocol which you can identify as meta elements that begin with og: This is a framework that is employed extensively by Facebook and so if you want to control how Facebook sees your screen, you’ll want to include the Open Graph markup in your pages. There are also Dublin Core metadata options that begin with dc: and a lot more.
Google does prefer the Schema.org markup, they are heavily involved in the development of this, and if you don’t have experience in looking at entity relationship diagrams and thinking about how all of the pieces parts of things fit together it can be a little bit overwhelming.
Data sets may have unique attributes within it from articles or maps or webpages. In order for the nearest location to show up as a card in that upper right-hand corner of the search results page, you actually do need to be listed in Google My Business. You should be able to enter all of your location data into the Google My Business listing, and then they would use that to feed those location cards in the Google search results, and then also the postal address is something that you could use for the address that you’ve got in your footer or other places throughout your site. Hopefully, you would be able to make a change just once in your template and not have to change it on every page assuming that you’ve got a site that inserts your footer content for you.
There are three different ways that you can present schema.org elements. So the one that Google recommends the most is the JSON-LD format, this is included as a block of script in the head of your page. You might want to do a bit of research to see if you could use JSON in combination with the structure of your current content. Another option is RDFa, and then Microdata both of which are expressed as inline properties in the body of your page.
If you are looking on a google.com search results page, and instead of a URL underneath the clickable title, you see the set of breadcrumbs from a site. They’re feeding that from this breadcrumbs markup.
One point about a website’s homepage is that you have the opportunity to control your site name as Google displays it in the search results. This is often shown as the first and most basic layer of a breadcrumbs list, but in the head of your page, you can add an item property of name to the title link and then it will use the text of the title link to inform your site name on the Google search results. One thing that I would caution you if you want to do this is, they recommend that it be simple and concise so that it doesn’t clutter up the search results essentially. For example, their name property is Google and not Google Inc.
Finally, you should know that you can trigger Google Site Search for your site, by telling it about potential actions and then you can tell it how to run a search on your site.
Final Thoughts
I hope this article was helpful in understanding some of the key elements of on-page or on-site SEO.
We covered Robots.txt, Sitemaps, Content Optimization, Duplicate Content, Hidden Content. Mobile-Friendly Site Structure, Page Speed, URL Structure, Site Security / HTTPS, Title Tags, Meta Description, Keywords, H1 H2 H3 Tags, Google Site Verification, Structured Data / Schema.org, and Rich Snippets.